

Divyam.AI's Performance vis a vis Microsoft and Nvidia Routers

Table of Contents
Today, you have a choice from a crowd of models which flex intelligence and capability. You have intelligence on tap, but which tap should you turn? Getting the right balance of power and proportionality when choosing your AI toolset plays a huge role in your success with AI deployments. In the context of LLMs, this challenge is crucial as it often bags the bulk of your AI expenditure. Divyam.AI addresses this exact challenge for you by helping you optimize your cost-performance balance for your GenAI deployments.

In this article, we present to you a comparative study of Divyam’s Router (the DAI Router in the diagram) capabilities vis-a-vis industry titans – Microsoft Model Router ,NVIDIA LLM Router.
To understand the comparison, let us dig into the principle on which Divyam’s Router works.
Suppose you want to assess the mental abilities and knowledge-based skills of thousands of students – what you would do is design a test with a questionnaire – and make them take the test and rank them on their performance in the test. Institutions have been doing this for decades using the psychometric framework called Item Response Theory (IRT), which has been around since 1968! IIRT is a family of psychometrically-grounded statistical models that takes the response matrix (i.e., how each student answered every question in the questionnaire) as input, and provides an estimate of “skill” possessed by each student, the “skill” needed to solve each question, along with their “difficulty”.
To draw a parallel, now consider each LLM as a student and evaluation benchmarks to be the test. Divyam extends the IRT family to enable the estimation of skill and difficulty of a hitherto unseen prompt, and utilizes the estimated skill of each LLM to estimate an ex-ante performance estimate.
Comparison of Routers
Routers are models that are trained to select the best large language model (LLM) to respond to a given prompt in real time. It uses a combination of preexisting models to provide high performance while saving on compute costs where possible, all packaged as a single model deployment.
The Divyam LLM Router employs a proprietary algorithm that assesses the skill required (and the difficulty level) of each prompt, and based on that, routes it to the available models for routing.
Dataset
For our comparative study, the benchmark that we have chosen is the MMLU-Pro , which tests the reasoning and knowledge capabilities of an LLM via a set of multiple choice questions spanning 14 subjects, such as Math, Physics, Computer Science, and Philosophy. Each question is presented with 10 possible answers, and an LLM, upon receiving a 5-shot prompt, must choose the sole correct answer. Randomly-chosen 20% samples (2,406 out of 12,032) serve as the test dataset, on which we report the performance.
LLM Performance
In the table below, we present the performance of a set of contemporary LLMs on MMLU-Pro. From the table, we can see that o4-mini has the best accuracy for this benchmark. Our subsequent tests will take o4-mini as the basis for our relative comparisons.

Results with Microsoft Model Router
The Microsoft Model Router (MS Router) is packaged as a single Azure AI Foundry model that you deploy. Notably, Model Router cannot be fine-tuned on your data.
The LLMs are chosen from a pre-existing set of models namely gpt-4.1, gpt-4.1-mini, gpt-4.1-nano, o4-mini. Notably, one cannot add or remove to this list.
Unlike Microsoft Model Router, Divyam routes your queries to the right LLM based on your preference for (a) cost optimization (b) performance optimization.
The graph below of Cost Savings vs Accuracy presents Router performance where the selection is limited to the MS router set of LLMs. Divyam’s Quality Optimization parameters have been tuned to suit Accuracy requirements to compare to MS Router. The different points on the graph for Divyam represents Divyam’s performance with different Quality Optimization parameters.This tuning is unique to Divyam and is not possible with MS Router.
You can see that for a comparable accuracy - Divyam (-5.1) and MS Router (-5.4), the Cost Savings for Divyam(Close to 60%) is almost double that of MS Router(close to 35%).
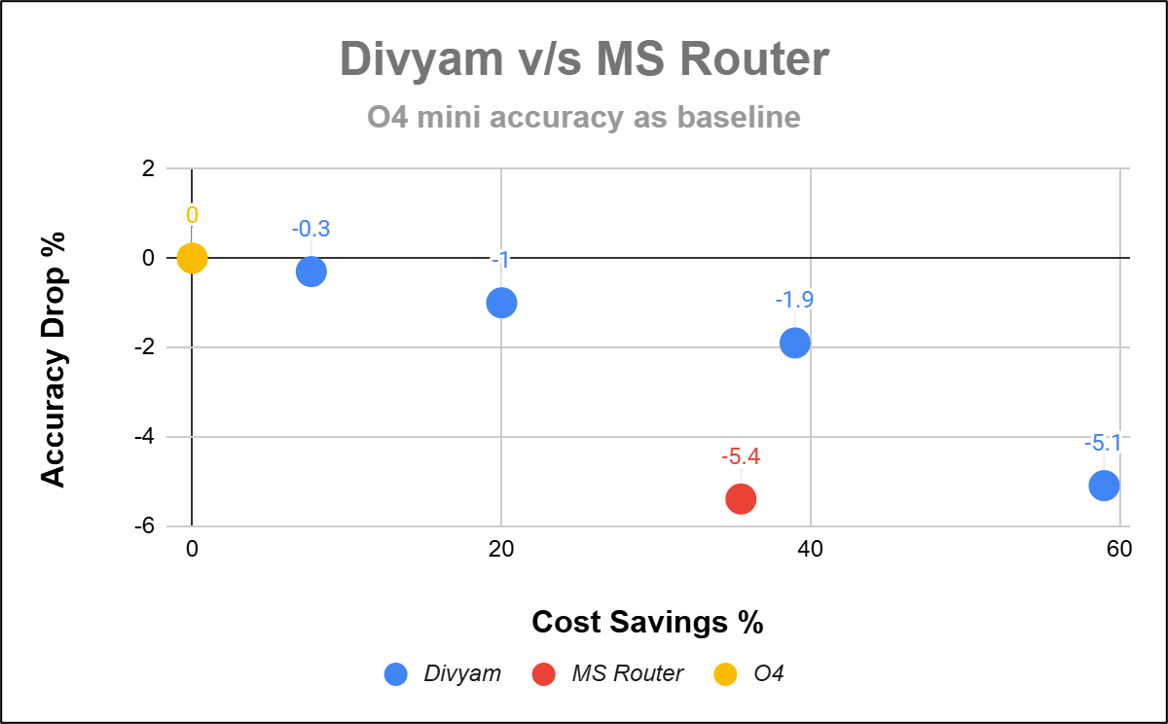
Whereas MS Router is stuck with its choices of LLMs, nothing restricts Divyam to add the right set of LLMs for our customer. After 3 Gemini models are added to Divyam Router (along with the ones Microsoft Model Router was already routing to), we notice a clear uptick in the cost-performance Pareto.
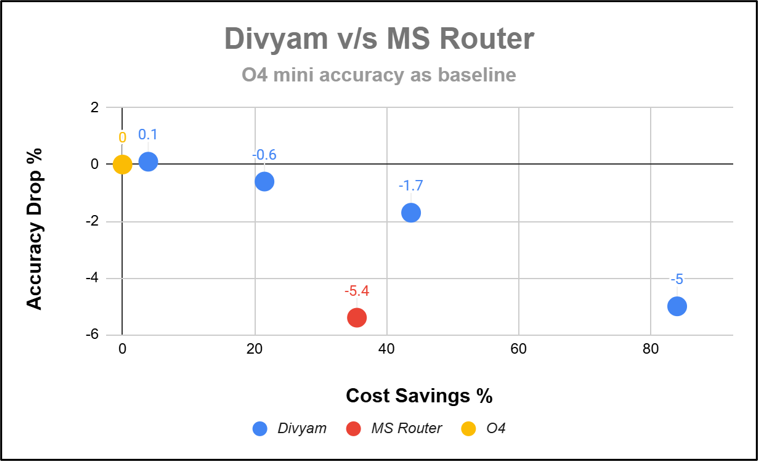
You can see from the graph above that Divyam does even better in terms of Cost Savings and Accuracy compared to MS Router. For the same relative accuracy - Divyam -5% and MS Router -5.4%, Divyam’s Cost Savings(around 84%) is nearly 3 times that of MS Router(around 35%).
Results with NVidia Router:
Divyam’s ability to prioritize cost and accuracy and separate and combined parameters are unique and yield better and desirable results in both cases.
The NVIDIA LLM Router can be configured with one of 3 Router Models – 1) task-router 2) complexity-router 3) intent-router – each, in turn, are powered by a (pre-LLM era) language model – Microsoft/DeBERTa-v3-base – which contains 86M parameters.
Furthermore, we consider the task-router and the intent-router unsuitable for our purpose and focus only on the complexity-router. The complexity-router classifies each prompt into one of 6 pre-defined classes (e.g., “Domain”), and routes all prompts in a class to a single, configurable LLM. In our specific example, all queries belonging to “Domain” are routed to the LLM, whereas everything else is routed to the SLM. The 4 points in the graph for NVidia are for different combinations of SLMs for the same LLM gpt4.1
We have tuned Divyam’s Quality Optimizer to “Priority Cost Saving” and “Priority Accuracy” represented as the 2 points in the graph.
All the comparisons is relative wrt to GPT 4.1 performance as baseline
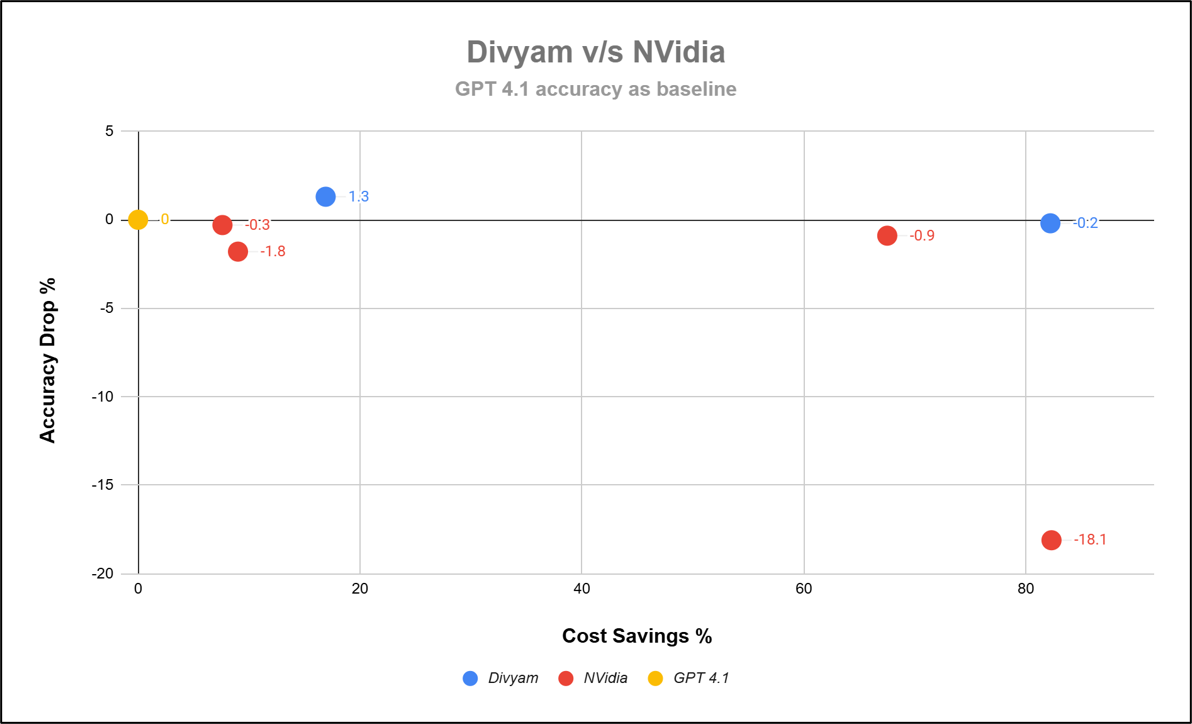
From the above graph you can see that for the same range of Cost Saving, Divyam(-0.2%) surpasses Nvidia(-18.1%) accuracy by a factor of 18 when tuned for Cost Saving. Also, Divyam’s Accuracy (1.3) surpasses that of GPT 4.1 when tuned for accuracy.
*Divyam’s MMLU-Pro Router Performance
The table below is a level deeper into the results in the above table. It shows how Divyam has used the number of dimensions of LLM abilities to get the LLM with the best probable value to be correct for that prompt. It also lists the distribution of LLMs chosen for the percentage of prompts from the test set.

For a similar test, the NVIDIA LLM Router insights are depicted in the below graphs.

In conclusion, we see that Divyam’s Router yields better Pareto for both Microsoft Router and NVIDIA Router, even though the philosophies of LLM choice are different in both comparisons. Divyam’s ability to prioritize cost and accuracy and separate and combined parameters are unique and yield better and desirable results in both cases. Moreover, Divyam spans cartel borders in the industry and can easily incorporate LLMs from all segments.
Stay tuned for more experimental results on the cost – performance ratios and deeper tests on confirming Divyam’s low running costs.
Explore More AI Insights
Stay ahead of the curve with our latest blogs on AI innovations, industry trends, and business transformations. Discover how intelligent systems are shaping the future—one breakthrough at a time.





Cut costs. Boost accuracy. Stay secure.
Smarter enterprise workflows start with Divyam.ai.